The proverbial slow and flaky CI isn't the failure of the developers or even the testing tools. It's the failure of the CI execution model we relied on for the last 20 years.
By switching from the old CI model, implemented as a graph of VMs, to the new one, implemented as a graph of tasks, we can solve both the flakiness and slowness.
In this blog post I'll explore why this is the case, and how you can do it by using Nx Cloud.
History of CI
It's easy to forget that Continuous Integration has been around for only 20 years. For reference, UI frameworks have been around since the 1970s.
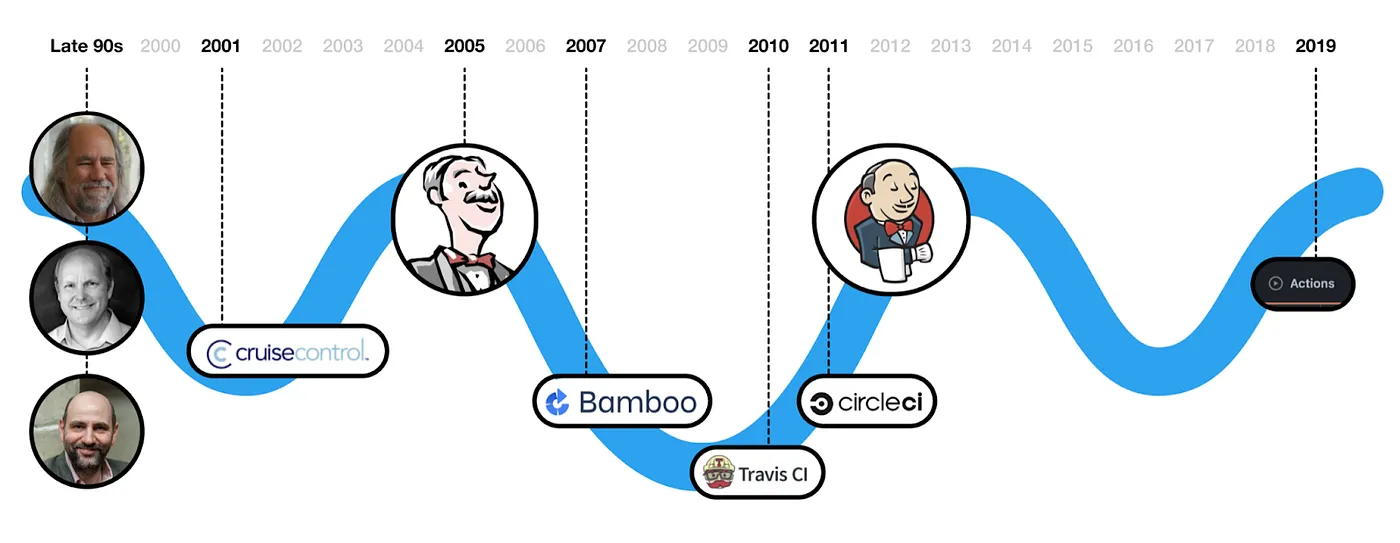
The innovation in the CI space has been primarily in where the CI process is described and how the configuration is written. How the CI actually works has largely remained the same.
How CI works
A traditional CI execution is a directed acyclic graph (DAG) of virtual machines (VMs). Each VM (often called a job) installs dependencies, restores NPM cache, and then runs the necessary steps to verify that, say, some tests pass.
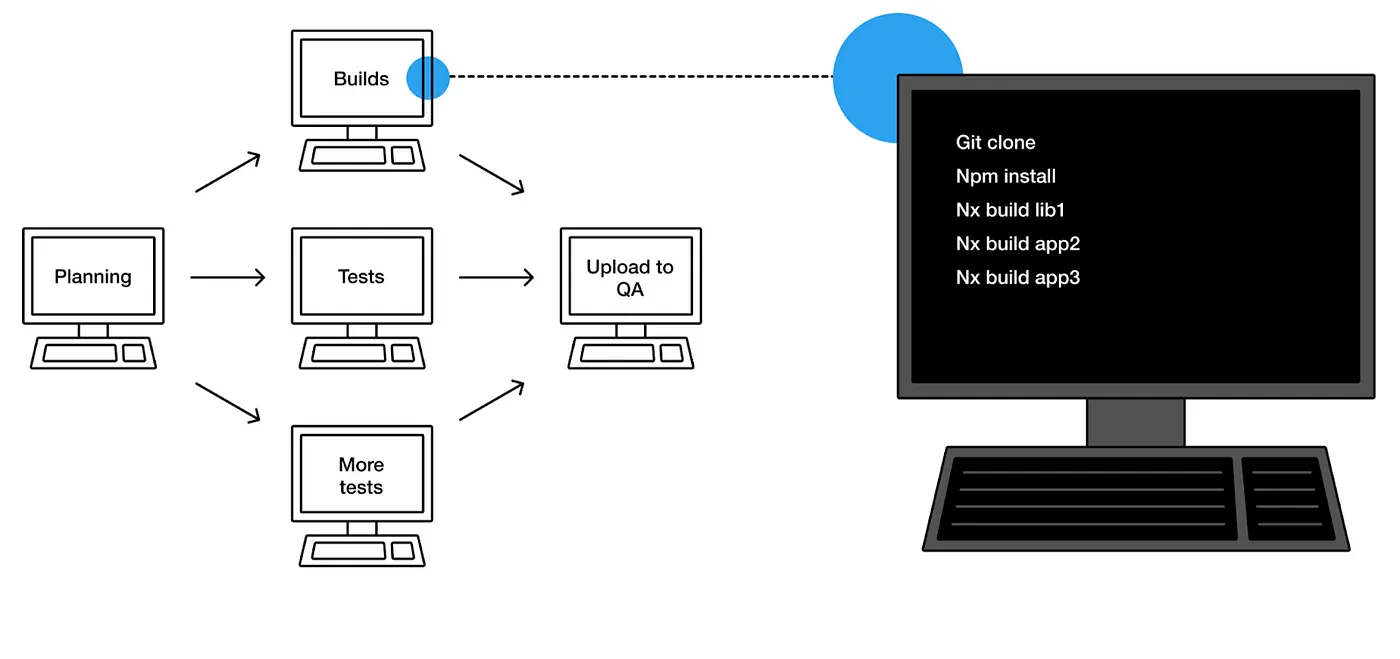
This CI execution is a distributed process, and a poorly designed one. It works reasonably well only when the number of jobs/VMs is very small and falls apart when the number gets larger.
Why does the current system not work?
Every distributed system needs efficient communication between nodes and the ability to tolerate failure.
The traditional CI execution model offers very basic means of communication: the status code propagation and ad-hoc ways of uploading/downloading files. Because the communication is effortful, in practice, it's either not done at all or very minimally.
To understand why the traditional CI execution model fails to handle failures, let's review the types of failures we can have.
Failures can be:
- hard (npm fails to install, nothing can run)
- soft (a test takes a lot longer than it should because, perhaps, due to an out-of-memory issue)
Focusing on the latter is just as important as focusing on the former. Slow CI is broken CI.
Tasks can fail:
- legitimately (a broken build)
- for external reasons (npm install fails cause npm is down)
- for unknown reasons (a flaky test)
The traditional CI execution model doesn't tolerate any of these failures.
Problem in numbers
Let's see how varying a few parameters affects the probability of the CI execution failing.
| Number of VMS | Avg Tests per VM | Flaky Test Probability | Slow Test Probability | Broken CI Builds (Flaky) | Slow CI Builds |
|---|---|---|---|---|---|
| 5 | 10 | 0.1% | 0.3% | 5% | 15% |
| 10 | 10 | 0.1% | 0.3% | 10% | 26% |
| 50 | 10 | 0.1% | 0.3% | 39% | 78% |
| 5 | 10 | 0.5% | 1% | 23% | 41% |
| 10 | 10 | 0.5% | 1% | 40% | 65% |
| 50 | 10 | 0.5% | 1% | 92% | 99% |
The result is much worse than most intuitively expect. For instance, assuming that an e2e test has 1 in 1000 chance (0.1%) of failing for a flaky reason, when the number of e2e tests reaches 500, the probability of the CI failing for a flaky reason reaches 39%, and the vast majority of CI executions are slowed down. Note, this is an exceptionally stable test suite. The bottom part of the table is more representative of a typical e2e suite, and the CI becomes "broken" at a much smaller scale.
One can try to fix it by increasing the robustness of the tests, but at some point, doing this is costly. If an e2e test has a 10% chance of a flaky failure, it's relatively easy to bring this number to 1%. Going from 1% to 0.5% is harder. Going from 0.5% to 0.1% is exceptionally hard and may be practically impossible. Testing complex systems is simply a difficult task.
This is the formula for the failed CI run:
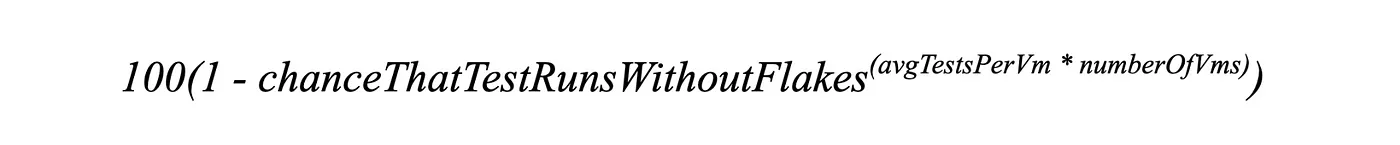
As you can see, as the number of tests grows, the exponent will make more and more CI executions fail for flaky reasons. In this model, the only way to combat it is by increasing $chanceThatTestRunsWithoutFlakes$, but the more tests you have, the more challenging this becomes. That's why a lot of projects move away from e2e tests or run them nightly (where they always fail).
It's not the team's fault. It's simply a losing battle with the current CI execution model.
We focused on the tests but the issue is more general.
VMs sometimes fail to execute their setup steps (e.g., some package fails to install), and in this model it results in a failed CI execution.
One of the setup steps can take a lot longer. Because the probabilities multiply, when the number of agents is high enough, this will happen frequently and will slow down a large number of CI executions. This is the formula for this case:
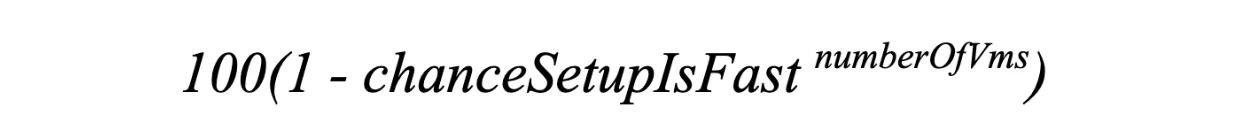
For instance, with 50 agents, if there is a 1% chance that NPM install will take an extra 5 minutes, 40% of CI executions will be affected by it, and your CI execution time goes from, say, 20m to 25m. The slowness doesn't amortize across agents.
Solution: Change the model
There is only that much gain to be had by optimizing the effectiveness and robustness of small units. Instead, we should focus on creating the systems we can use to achieve incredible performance and resilience with ordinary small units.
The CI model above has a fundamental problem: it is static. It defines a fixed number of VM, where each has a unique job to do. The VMs aren't interchangeable. If one of them fails or is slow, no other VM can help it.
Nx Cloud introduces an entirely different model. Instead of the graph of VMs, the CI execution is expressed as a graph of tasks.
By adding the following line…
❯
npx nx-cloud start-ci-run --distribute-on="3 linux-medium-js"
... you are telling Nx Cloud to create five Nx Agents to execute all the tasks from all the commands that will follow.
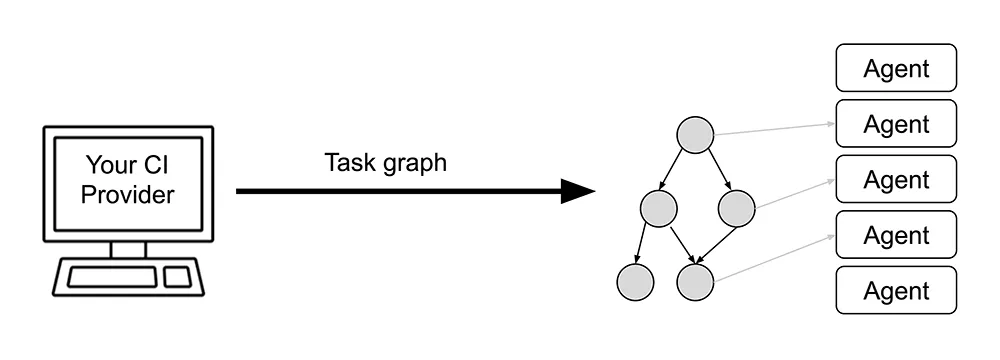
Nx Agents are essentially VMs, but they are different from the ones in the traditional CI execution model.
You can imagine the traditional CI model as a team where every member is given a unique set of tasks. If a team member gets sick, their work won't be completed, and the CI execution will fail. If a team member is slow, no one can help them. Everyone will just have to wait for them to complete their assignment.
The Nx Agent model is a team where the work doesn't get assigned ahead of time. Instead, there is a pile of work in the middle of the room, and every team member can take any piece of work and do it. Once they are done with one piece of work, they can take another one. If a member gets sick, a slightly smaller team can complete the job. If a member is slow, the other members will split the work. In practice, it is even better than this. If an Nx Agent fails, another one will be started in its place.
Solution in numbers
Let's examine the two cases above.
First, npm install failing will not break the build. Nx Cloud will simply spawn another Nx Agent in its place.
The slowness of the npm install will affect the CI execution but in a very different way because it will be amortized across agents. So with 50 agents executing, adding 5 minutes to an npm install of one of the agents, will only increase the CI execution time by 6 seconds _(5 _ 60 / 50)*.
Second, Nx Cloud knows what specific tests are flaky, and if they fail, it will rerun them on a separate agent. Rerunning them on a separate agent is crucial. Often flaky failures will continue to fail when rerun on the same agent.
This is the formula:
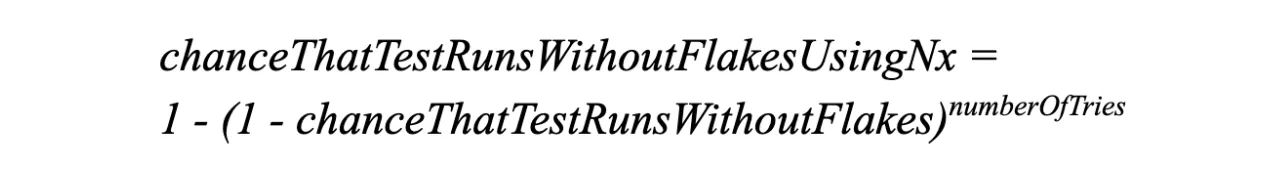
If we examine the case above, where the test flaky happened 1 in 1000, two retries will result in 1 - (1–0.999)^3^ = 0.999999999, which brings the likelihood of the CI failing for a flaky reason to 0.000005%.
The Nx Cloud model handles both hard and soft failures. Your agents can crush or be slow - doesn't matter. Your tests can fail or be slow - doesn't matter. Your CI will complete fast.
Can we fix the traditional model?
It's possible to make the traditional CI model more reliable but the solution isn't adequate for large workspaces.
For instance, in principle, it is possible to add retrying logic to every CI step. It's cumbersome and widely-used CI steps (e.g., popular Github Actions) don't do it. But even if you manage to wrap every step, this isn't bulletproof because many failures are unrecoverable.
Slow setup steps simply cannot be fixed or amortized.
One can add rerunning the same e2e test multiple times on the same machine to deal with flakes but there are numerous problems with this.
One of the most common reasons why e2e tests are flaky is because they create side effects. For instance, they can create records in the db. They have some logic to clean it up, but it is imperfect. Or tests can assume that some fixture will be modified once. Ideally, this would never happen, but in practice it happens all the time. Nx Cloud will always retry the same task on a different agent to avoid this problem.
Don't forget, you actually need to know which tests are flaky. Most of your failures will be legitimate so rerunning all the tests will make you CI slow. And those reruns cannot be amortized.
There are other practical problems. If you have enough VMs, rebuilding the app under test on each of them becomes impractical, so you need to build it once and send it to all your VMs. Your e2e tests have to be partitioned into small units to allow for efficient distribution. And the list of problems goes on.
The traditional CI model is not really fixable because it makes no assumptions about its execution steps and, as a result, it cannot do anything automatically.
The Nx Cloud model only works when your build system and CI are built for each other. The CI needs to know the task graph, what a task requires, what files it creates. Without this information, nothing can be distributed, nothing can be rerun or deflaked. Nx and Nx Cloud (with Nx Agents) fit together. Nx can run tasks locally or can pass this metadata to Nx Cloud which will orchestrate the same computation across many VMs. Nx Cloud will move the right files to the right agents, split large e2e test suites, and deflake the tests automatically. This only works because of the assumptions made by the CI and the build tool.
Performance
The focus of this post is robustness. But the Nx Cloud model is also significantly faster and more efficient. Because Nx Agents are interchangeable, Nx Cloud will use a different number of agents depending on the size of the code change. It can split the work more effectively across agents, reduce the number of npm installs required, split large e2e suites into smaller units and more.
Summary
The spirit of this post is similar to Alan Kay's quote, "A change of perspective is worth 80 IQ points". By changing the CI execution model, Nx Cloud makes some difficult, almost unsolvable, problems easy.
You can learn more about Nx Cloud on our docs.
Nx Cloud Pro includes a 2-month free trial that is definitely worth trying out if you're curious what Cloud Pro can do for your CI. You can try out Nx Agents, e2e test splitting, deflaking and more. Learn more about Nx Cloud Pro.